Mengenal Algoritma K-Nearest Neighbors (KNN) dan Aplikasinya dalam Machine Learning
TweetDalam dunia machine learning, algoritma K-Nearest Neighbors (KNN) merupakan salah satu metode klasifikasi dan regresi yang populer dan banyak digunakan. Algoritma ini termasuk dalam kategori algoritma supervised learning, di mana model dilatih menggunakan data berlabel untuk memprediksi label atau nilai target pada data baru. Meskipun sederhana dalam konsep, KNN telah terbukti efektif dalam berbagai kasus penggunaan dan menjadi salah satu algoritma dasar yang penting untuk dipahami dalam machine learning.
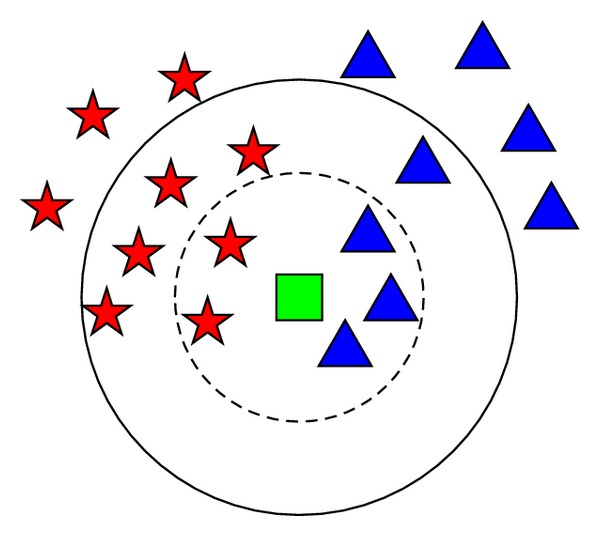
Cara Kerja Algoritma KNN
Algoritma KNN bekerja dengan mengidentifikasi k tetangga terdekat (nearest neighbors) dari data baru yang ingin diprediksi, berdasarkan jarak atau kesamaan fitur-fitur yang dimilikinya dengan data dalam kumpulan data pelatihan. Nilai k merupakan jumlah tetangga terdekat yang akan dipertimbangkan dalam proses prediksi. Setelah k tetangga terdekat diidentifikasi, algoritma KNN akan memprediksi label atau nilai target untuk data baru tersebut berdasarkan mayoritas label atau rata-rata nilai target dari k tetangga terdekat.
Dalam kasus klasifikasi, algoritma KNN akan memprediksi label kelas dengan menghitung jumlah label mayoritas dari k tetangga terdekat. Sementara dalam kasus regresi, algoritma KNN akan memprediksi nilai numerik dengan menghitung rata-rata dari nilai target k tetangga terdekat.
Salah satu aspek penting dalam algoritma KNN adalah pemilihan metrik jarak yang akan digunakan untuk mengukur kesamaan atau kedekatan antara data baru dengan data dalam kumpulan data pelatihan. Beberapa metrik jarak yang umum digunakan dalam KNN antara lain jarak Euclidean, jarak Manhattan, dan jarak Minkowski. Pemilihan metrik jarak yang tepat dapat mempengaruhi kinerja algoritma KNN secara signifikan.
Kelebihan dan Kekurangan Algoritma KNN
Algoritma KNN memiliki beberapa kelebihan yang membuatnya menjadi pilihan yang menarik dalam banyak kasus penggunaan. Berikut adalah beberapa keunggulan utama dari algoritma ini:
- Sederhana dan mudah diimplementasikan: Konsep dasar dari KNN sangat mudah dipahami dan diimplementasikan dalam kode, sehingga memudahkan proses pengembangan model.
- Tidak memerlukan pelatihan rumit: Algoritma KNN tidak melakukan pelatihan model seperti pada algoritma lainnya, melainkan hanya menyimpan seluruh data pelatihan dalam memori.
- Efektif untuk data non-linier: KNN dapat menangani hubungan non-linier antara fitur dan label dengan baik, tanpa perlu membuat asumsi tentang distribusi data.
- Tidak rentan terhadap overfitting: Karena algoritma KNN tidak melakukan pelatihan model secara eksplisit, maka risiko overfitting relatif lebih rendah dibandingkan dengan algoritma lain.
Namun, algoritma KNN juga memiliki beberapa kekurangan yang perlu dipertimbangkan, antara lain:
- Sensitivitas terhadap skala fitur: Algoritma KNN sangat sensitif terhadap skala fitur yang berbeda, sehingga normalisasi atau penskalaan fitur menjadi penting untuk mendapatkan kinerja yang optimal.
- Komputasi yang mahal: Dalam kasus data besar, algoritma KNN dapat menjadi lambat dan memakan banyak sumber daya komputasi karena harus menghitung jarak untuk setiap data baru dengan seluruh data pelatihan.
- Sensitif terhadap outlier: Algoritma KNN dapat terpengaruh oleh outlier atau data yang menyimpang dalam kumpulan data pelatihan, yang dapat menyebabkan prediksi yang tidak akurat.
- Pemilihan nilai k yang optimal: Nilai k (jumlah tetangga terdekat) yang dipilih dapat mempengaruhi kinerja algoritma secara signifikan, sehingga diperlukan teknik khusus seperti validasi silang untuk menentukan nilai k yang optimal.
Aplikasi Algoritma KNN
Algoritma KNN telah banyak diaplikasikan dalam berbagai bidang dan kasus penggunaan, baik untuk tugas klasifikasi maupun regresi. Berikut adalah beberapa contoh aplikasi algoritma KNN:
- Pengenalan pola: KNN dapat digunakan untuk mengenali pola dalam data seperti pengenalan tulisan tangan, pengenalan wajah, atau pengenalan suara.
- Rekomendasi sistem: Dalam sistem rekomendasi, KNN dapat digunakan untuk merekomendasikan item (misalnya film, musik, atau produk) berdasarkan kesamaan dengan preferensi pengguna lain.
- Prediksi cuaca: Algoritma KNN dapat digunakan untuk memprediksi kondisi cuaca di masa depan berdasarkan data historis seperti suhu, kelembaban, dan tekanan udara.
- Deteksi anomali: Dengan mengidentifikasi data yang jauh dari tetangga terdekatnya, KNN dapat digunakan untuk mendeteksi anomali atau outlier dalam kumpulan data.
- Klasterisasi data: Meskipun KNN pada dasarnya adalah algoritma supervised learning, namun juga dapat digunakan untuk tugas klasterisasi data (unsupervised learning) dengan mengelompokkan data berdasarkan kedekatannya.
- Analisis sentimen: Dalam analisis sentimen pada teks atau data lainnya, KNN dapat digunakan untuk mengklasifikasikan sentimen (positif, negatif, atau netral) berdasarkan kesamaan dengan data sentimen yang sudah dilabeli.
Algoritma KNN terus menjadi salah satu algoritma yang populer dan banyak digunakan dalam machine learning, terutama karena kesederhanaannya dan kemampuannya dalam menangani hubungan non-linier antara fitur dan label. Meskipun memiliki beberapa kekurangan, algoritma ini tetap menjadi pilihan yang baik untuk berbagai kasus penggunaan, baik sebagai model mandiri maupun sebagai bagian dari ensemble dengan algoritma lainnya.
Dengan memahami konsep dasar, kelebihan, dan kekurangan algoritma KNN, praktisi dan peneliti di bidang machine learning dapat mengoptimalkan penggunaannya dalam proyek-proyek mereka dan mencapai kinerja yang lebih baik dalam tugas-tugas klasifikasi dan regresi.
Bagi teman teman yang memiliki judul skripsi berkaitan dengan Algoritma KNN bisa menghubungi kami, dan dapatkan spesial price

Portofolio
Berikut kami tampilkan beberapa portofolio yang pernah kami kerjakan. Lihat Selengkapnya


-untuk-Deteksi-Tumor-Otak.jpg)







-untuk-Prediksi-Pergerakan-Harga-Forex.jpg)











Oleh : Firda
Tanggal Publikasi :
Bebas DP bagi Skripsi dengan Judul dan Konsep yang Jelas
Sisa Kuota 2
Sisa Waktu : : : :































