Memahami Generalisasi, Overfitting dan Underfitting dalam machine learning
Tweet
Dalam dunia machine learning, tiga konsep penting yang sering dibahas adalah generalisasi, overfitting, dan underfitting. Ketiganya memiliki peran krusial dalam menentukan seberapa baik model machine learning dapat mempelajari pola dari data pelatihan dan membuat prediksi akurat pada data yang belum pernah dilihat sebelumnya. Pemahaman yang mendalam tentang konsep-konsep ini sangat penting untuk membangun model yang efektif dan dapat diandalkan.
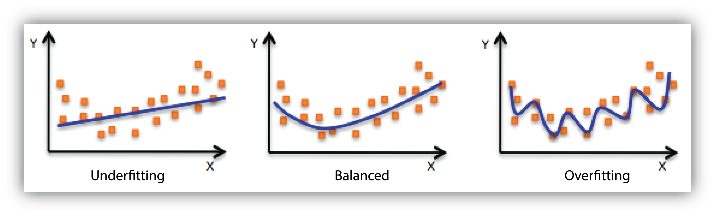
1. Generalisasi
Generalisasi adalah kemampuan model machine learning untuk mempelajari pola umum dari data pelatihan dan menggunakannya untuk membuat prediksi yang akurat pada data baru yang belum pernah dilihat sebelumnya. Inilah tujuan utama dari machine learning: membangun model yang dapat mengenali pola dan membuat prediksi yang bermanfaat pada data yang belum diketahui.
Dalam konteks machine learning, generalisasi yang baik berarti model dapat mempelajari konsep yang mendasari data pelatihan dan menerapkannya pada data baru dengan cara yang bermakna dan akurat. Model yang memiliki kemampuan generalisasi yang tinggi akan memiliki kinerja yang konsisten, baik pada data pelatihan maupun data pengujian yang belum pernah dilihat sebelumnya.
Beberapa faktor yang dapat mempengaruhi kemampuan generalisasi model machine learning antara lain:
a. Kompleksitas model: Model yang terlalu sederhana atau terlalu kompleks dapat menyebabkan masalah generalisasi. Model yang terlalu sederhana mungkin tidak dapat menangkap kompleksitas yang ada dalam data, sementara model yang terlalu kompleks dapat menyebabkan overfitting (akan dibahas lebih lanjut).
b. Ukuran dan kualitas data pelatihan: Semakin banyak data pelatihan yang berkualitas baik, semakin besar peluang model untuk mempelajari pola yang umum dan menghindari overfitting atau underfitting.
c. Regularisasi: Teknik regularisasi, seperti penambahan penalti pada kompleksitas model, dapat membantu meningkatkan kemampuan generalisasi dengan mencegah overfitting.
d. Validasi silang (cross-validation): Teknik validasi silang dapat digunakan untuk mengevaluasi kemampuan generalisasi model pada subset data yang berbeda dan memastikan bahwa model tidak terlalu overfitting atau underfitting pada satu set data tertentu.
Tujuan utama machine learning adalah membangun model yang dapat menggeneralisasi dengan baik, sehingga dapat membuat prediksi yang akurat pada data baru yang belum pernah dilihat sebelumnya.
2. Overfitting
Overfitting adalah situasi di mana model machine learning mempelajari pola yang terlalu spesifik dari data pelatihan, termasuk noise dan keunikan data individu, sehingga gagal menangkap pola umum yang lebih penting. Ini menyebabkan model memiliki kinerja yang sangat baik pada data pelatihan, tetapi kinerjanya menurun secara signifikan pada data baru yang belum pernah dilihat sebelumnya.
Overfitting sering terjadi ketika model terlalu kompleks atau memiliki terlalu banyak parameter dibandingkan dengan jumlah data pelatihan yang tersedia. Model yang terlalu kompleks cenderung mempelajari noise dan keunikan data pelatihan, bukan pola umum yang dapat digeneralisasi ke data baru.
Beberapa indikasi overfitting antara lain:
a. Akurasi pelatihan sangat tinggi, tetapi akurasi pengujian jauh lebih rendah. b. Model memiliki kinerja yang sangat baik pada data pelatihan, tetapi gagal memprediksi data baru dengan akurat. c. Model sangat sensitif terhadap perubahan kecil pada data pelatihan.
Untuk mengatasi overfitting, ada beberapa teknik yang dapat digunakan, seperti:
a. Regularisasi: Menambahkan penalti pada kompleksitas model untuk mencegah overfitting. b. Early stopping: Menghentikan pelatihan model pada titik di mana akurasi validasi mulai menurun, sebelum overfitting terjadi. c. Dropout: Teknik regularisasi yang secara acak menonaktifkan beberapa neuron dalam jaringan saraf tiruan selama pelatihan untuk mencegah overfitting. d. Augmentasi data: Meningkatkan jumlah dan variasi data pelatihan dengan teknik seperti rotasi, pembesaran, atau penambahan noise pada gambar.
Overfitting dapat mengurangi kemampuan generalisasi model dan menyebabkan kinerja yang buruk pada data baru. Oleh karena itu, penting untuk memantau dan mencegah overfitting selama pelatihan model machine learning.
3. Underfitting
Underfitting adalah situasi di mana model machine learning tidak mampu mempelajari pola yang cukup kompleks dari data pelatihan. Ini terjadi ketika model terlalu sederhana atau tidak cukup fleksibel untuk menangkap kompleksitas yang ada dalam data.
Underfitting sering terjadi ketika model tidak memiliki cukup parameter atau kompleksitas untuk mempelajari pola yang ada dalam data pelatihan. Model yang terlalu sederhana akan gagal menangkap hubungan dan pola yang lebih kompleks, sehingga menghasilkan akurasi yang rendah, baik pada data pelatihan maupun data pengujian.
Beberapa indikasi underfitting antara lain:
a. Akurasi pelatihan dan akurasi pengujian sama-sama rendah. b. Model tidak dapat mempelajari pola yang ada dalam data pelatihan dengan baik. c. Model tidak dapat menangkap kompleksitas yang ada dalam data.
Untuk mengatasi underfitting, ada beberapa pendekatan yang dapat digunakan, seperti:
a. Meningkatkan kompleksitas model: Menambahkan lebih banyak parameter atau lapisan tersembunyi pada model untuk meningkatkan fleksibilitasnya dalam mempelajari pola yang lebih kompleks. b. Menggunakan fitur yang lebih informatif: Mengekstraksi fitur yang lebih relevan dan informatif dari data, sehingga model dapat mempelajari pola yang lebih kompleks. c. Menggunakan model yang lebih kompleks: Menggunakan model yang lebih kompleks, seperti jaringan saraf tiruan yang lebih dalam atau model ensemble, yang memiliki kemampuan untuk menangkap pola yang lebih rumit.
Underfitting dapat menyebabkan model kehilangan informasi penting dan gagal menangkap pola yang relevan dalam data. Ini dapat menurunkan kinerja model secara keseluruhan dan membatasi kemampuan generalisasinya.
Dalam praktiknya, overfitting dan underfitting merupakan dua masalah yang saling bertentangan. Ketika berusaha menghindari overfitting, kita dapat berakhir dengan model yang terlalu sederhana dan mengalami underfitting. Sebaliknya, ketika berusaha menghindari underfitting, kita dapat berakhir dengan model yang terlalu kompleks dan mengalami overfitting.
Tugas utama dalam membangun model machine learning yang efektif adalah mencapai keseimbangan yang tepat antara kompleksitas model dan kemampuan generalisasi. Ini melibatkan proses trial-and-error, evaluasi kinerja model pada data validasi, dan penyesuaian parameter serta teknik regularisasi yang sesuai.
Pemahaman yang mendalam tentang konsep generalisasi, overfitting, dan underfitting sangat penting dalam machine learning. Dengan memahami konsep-konsep ini, para praktisi machine learning dapat membuat keputusan yang lebih baik
Bagi teman teman yang ingin memesan aplikasi skipsi berbasis machile learing dapat menghubungi kami. kami juga menerima jasa pembuatan aplikasi skripsi jurusan teknik informatika,sistem informasi dan ilmu komputer. dapatkan harga menarik
Portofolio
Berikut kami tampilkan beberapa portofolio yang pernah kami kerjakan. Lihat Selengkapnya


-untuk-Deteksi-Tumor-Otak.jpg)







-untuk-Prediksi-Pergerakan-Harga-Forex.jpg)











Oleh : Firda
Tanggal Publikasi :
Bebas DP bagi Skripsi dengan Judul dan Konsep yang Jelas
Sisa Kuota 2
Sisa Waktu : : : :































