Kelebihan dan Kekurangan Algoritma K-Means
TweetDalam dunia machine learning, khususnya dalam bidang unsupervised learning, algoritma K-Means merupakan salah satu algoritma clustering yang paling populer dan banyak digunakan. Algoritma ini bertujuan untuk mengelompokkan data ke dalam sejumlah cluster atau kelompok berdasarkan kesamaan fitur-fitur yang dimiliki oleh setiap data.
Algoritma K-Means telah banyak diaplikasikan dalam berbagai bidang, seperti pengelompokan pelanggan, segmentasi pasar, pengelompokan gambar, analisis data genomik, dan banyak lagi. Oleh karena itu, pemahaman yang mendalam tentang algoritma ini sangat penting bagi praktisi dan peneliti di bidang machine learning dan data mining.
Konsep Dasar Algoritma K-Means
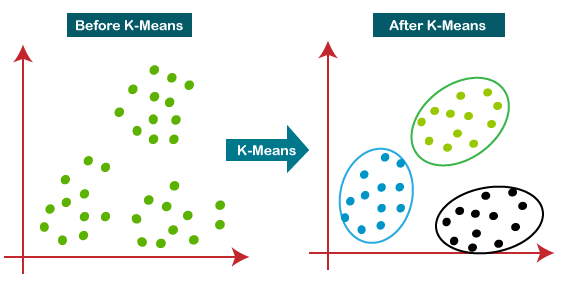
Algoritma K-Means bekerja dengan membagi data menjadi sejumlah cluster (k) berdasarkan kedekatannya dengan pusat cluster (centroid). Setiap data akan dikelompokkan ke dalam cluster yang memiliki pusat terdekat dengannya. Proses clustering dilakukan secara iteratif, di mana centroid setiap cluster akan terus diperbarui hingga tidak ada lagi perpindahan data antar cluster.
Algoritma K-Means memiliki beberapa langkah utama, yaitu:
- Inisialisasi pusat cluster (centroid) awal Pada tahap ini, algoritma akan memilih k buah data secara acak atau menggunakan teknik tertentu sebagai centroid awal.
- Pengelompokan data ke dalam cluster terdekat Setelah centroid awal ditentukan, setiap data akan dikelompokkan ke dalam cluster yang memiliki centroid terdekat dengannya, biasanya dengan menggunakan metrik jarak seperti jarak Euclidean atau Manhattan.
- Pembaruan centroid cluster Setelah semua data dikelompokkan, centroid setiap cluster akan diperbarui dengan menghitung rata-rata dari semua data yang berada dalam cluster tersebut.
- Iterasi dan konvergensi Langkah 2 dan 3 akan diulang secara iteratif hingga tidak ada lagi perpindahan data antar cluster atau kriteria konvergensi lainnya tercapai.
Kelebihan dan Kekurangan Algoritma K-Means
Seperti algoritma lainnya, algoritma K-Means memiliki kelebihan dan kekurangan dalam implementasinya. Berikut adalah beberapa kelebihan dan kekurangan utama dari algoritma K-Means:
Kelebihan:
- Sederhana dan mudah diimplementasikan Algoritma K-Means memiliki konsep yang sederhana dan mudah dipahami, sehingga relatif mudah untuk diimplementasikan dalam kode program.
- Efisien untuk dataset besar Algoritma K-Means dapat berjalan dengan efisien pada dataset yang besar, terutama jika diimplementasikan dengan teknik optimasi tertentu.
- Dapat digunakan untuk berbagai jenis data Algoritma K-Means dapat digunakan untuk mengelompokkan berbagai jenis data, seperti data numerik, teks, gambar, atau data lainnya, asalkan memiliki fitur yang dapat direpresentasikan dalam ruang vektor.
- Hasil clustering yang intuitif Hasil clustering yang dihasilkan oleh algoritma K-Means cukup intuitif dan mudah diinterpretasikan, terutama jika data memiliki struktur cluster yang jelas.
Kekurangan:
- Memerlukan penentuan jumlah cluster (k) sebelumnya Algoritma K-Means memerlukan penentuan jumlah cluster (k) sebelum proses clustering dilakukan. Penentuan nilai k yang optimal dapat menjadi tantangan tersendiri, terutama jika tidak ada informasi awal tentang struktur data.
- Sensitif terhadap outlier dan inisialisasi centroid awal Algoritma K-Means sangat sensitif terhadap outlier (data yang menyimpang) dan inisialisasi centroid awal. Jika terdapat outlier dalam data atau centroid awal dipilih dengan buruk, hasil clustering dapat menjadi kurang optimal.
- Hanya dapat mendeteksi cluster berbentuk bulat (spherical) Algoritma K-Means hanya dapat mendeteksi cluster yang berbentuk bulat atau spherical dengan baik. Jika struktur cluster dalam data memiliki bentuk yang tidak teratur, algoritma ini dapat mengalami kesulitan dalam mengelompokkannya dengan akurat.
- Dapat terjebak dalam optimum lokal Dalam beberapa kasus, algoritma K-Means dapat terjebak dalam optimum lokal, di mana proses iteratif tidak dapat mencapai solusi optimal global.
Meskipun memiliki kekurangan tersebut, algoritma K-Means tetap menjadi salah satu algoritma clustering yang paling populer dan banyak digunakan dalam berbagai aplikasi praktis. Untuk mengatasi kekurangan-kekurangan tersebut, telah dikembangkan berbagai variasi dan penyempurnaan dari algoritma K-Means, seperti K-Means++, K-Medoids, dan K-Means dengan inisialisasi centroid yang lebih baik.
Portofolio
Berikut kami tampilkan beberapa portofolio yang pernah kami kerjakan. Lihat Selengkapnya


-untuk-Deteksi-Tumor-Otak.jpg)







-untuk-Prediksi-Pergerakan-Harga-Forex.jpg)











Oleh : Firda
Tanggal Publikasi :
Bebas DP bagi Skripsi dengan Judul dan Konsep yang Jelas
Sisa Kuota 2
Sisa Waktu : : : :































