Istilah dalam machine learning yang harus dipahami oleh mahasiswa tingkat akhir
Tweet
Dalam dunia machine learning, terdapat banyak istilah dan metrik yang digunakan untuk mengevaluasi dan menganalisis kinerja model. Beberapa istilah penting yang sering digunakan antara lain confusion matrix, precision, recall, F1-score, accuracy, dan lain-lain. Pemahaman terhadap istilah-istilah ini sangat penting untuk memahami kinerja model dan mengoptimalkan hasilnya. Berikut adalah penjelasan mengenai istilah-istilah tersebut.
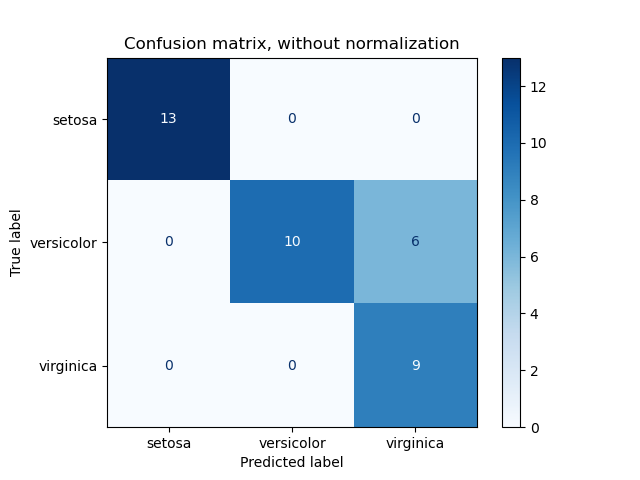
- Confusion Matrix adalah alat visualisasi yang digunakan untuk mengevaluasi kinerja model dalam tugas klasifikasi. Matriks ini membandingkan hasil prediksi model dengan nilai aktual atau ground truth. Confusion matrix terdiri dari empat komponen:
- True Positive (TP): Jumlah data yang diprediksi positif dan benar-benar positif.
- True Negative (TN): Jumlah data yang diprediksi negatif dan benar-benar negatif.
- False Positive (FP): Jumlah data yang diprediksi positif tetapi sebenarnya negatif.
- False Negative (FN): Jumlah data yang diprediksi negatif tetapi sebenarnya positif.
Confusion matrix memberikan gambaran yang jelas tentang kinerja model dalam mengklasifikasikan data dan membantu mengidentifikasi jenis kesalahan yang dilakukan oleh model.
- Precision Precision adalah metrik yang mengukur seberapa banyak prediksi positif yang benar-benar positif. Precision dihitung dengan membagi jumlah True Positive dengan jumlah total prediksi positif (True Positive + False Positive). Rumus precision adalah:
Precision = TP / (TP + FP)
Nilai precision berkisar antara 0 hingga 1, dengan nilai 1 menunjukkan precision yang sempurna. Precision penting dalam kasus di mana kesalahan False Positive sangat tidak diinginkan.
- Recall Recall adalah metrik yang mengukur seberapa banyak data positif yang diprediksi dengan benar. Recall dihitung dengan membagi jumlah True Positive dengan jumlah total data positif (True Positive + False Negative). Rumus recall adalah:
Recall = TP / (TP + FN)
Sama seperti precision, nilai recall juga berkisar antara 0 hingga 1, dengan nilai 1 menunjukkan recall yang sempurna. Recall penting dalam kasus di mana kesalahan False Negative sangat tidak diinginkan.
- F1-Score F1-score adalah metrik yang menggabungkan precision dan recall dengan cara yang seimbang. F1-score dihitung dengan mengambil rata-rata harmonis dari precision dan recall. Rumus F1-score adalah:
F1-score = 2 * (Precision * Recall) / (Precision + Recall)
F1-score berguna ketika kita ingin mempertimbangkan baik precision maupun recall dalam evaluasi model. Nilai F1-score berkisar antara 0 hingga 1, dengan nilai 1 menunjukkan kinerja yang sempurna.
- Accuracy Accuracy adalah metrik yang mengukur seberapa sering model memprediksi dengan benar, baik untuk kelas positif maupun negatif. Accuracy dihitung dengan membagi jumlah total prediksi yang benar (True Positive + True Negative) dengan jumlah total data. Rumus accuracy adalah:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Accuracy sering digunakan sebagai metrik evaluasi yang sederhana, tetapi dapat memberikan gambaran yang tidak lengkap dalam kasus di mana terdapat ketidakseimbangan kelas (class imbalance) dalam data.
- Receiver Operating Characteristic (ROC) Curve dan Area Under the Curve (AUC) ROC Curve adalah plot grafik yang menggambarkan hubungan antara True Positive Rate (TPR) dan False Positive Rate (FPR) pada berbagai ambang batas (threshold) klasifikasi. TPR, yang juga dikenal sebagai recall, dihitung dengan membagi True Positive dengan jumlah total data positif. FPR dihitung dengan membagi False Positive dengan jumlah total data negatif.
AUC (Area Under the Curve) adalah metrik yang mengukur area di bawah kurva ROC. Nilai AUC berkisar antara 0 hingga 1, dengan nilai 1 menunjukkan kinerja klasifikasi yang sempurna. AUC memberikan gambaran tentang kinerja model secara keseluruhan dalam membedakan kelas positif dan negatif.
- Cross-Validation Cross-Validation adalah teknik yang digunakan untuk mengevaluasi kinerja model secara lebih umum dan menghindari overfitting pada data pelatihan. Dalam cross-validation, data dibagi menjadi beberapa subset, dan model dilatih dan dievaluasi secara berulang dengan menggunakan subset yang berbeda sebagai data pelatihan dan data pengujian. Metrik seperti accuracy, precision, recall, dan F1-score dapat dihitung pada setiap iterasi cross-validation, dan nilai rata-rata dari metrik-metrik ini digunakan sebagai estimasi kinerja model yang lebih umum.
- Bias dan Variance Bias dan variance adalah konsep penting dalam machine learning yang berkaitan dengan kinerja model. Bias mengacu pada seberapa jauh model menyimpang dari fungsi target yang sebenarnya, sedangkan variance mengacu pada seberapa banyak model bervariasi untuk data pelatihan yang berbeda.
Model dengan bias tinggi cenderung terlalu sederhana dan tidak dapat menangkap kompleksitas dalam data, sementara model dengan variance tinggi cenderung overfitting pada data pelatihan dan tidak dapat menggeneralisasi dengan baik pada data baru.
Tujuan dalam pelatihan model adalah mencapai keseimbangan antara bias dan variance yang rendah untuk mendapatkan kinerja yang optimal.
- Underfitting dan Overfitting Underfitting terjadi ketika model terlalu sederhana dan tidak dapat menangkap pola yang ada dalam data, menyebabkan kinerja yang buruk baik pada data pelatihan maupun data pengujian. Overfitting terjadi ketika model terlalu kompleks dan menyesuaikan diri terlalu dekat dengan data pelatihan, termasuk noise, sehingga kinerja pada data pengujian menjadi buruk meskipun kinerja pada data pelatihan sangat baik.
Teknik seperti regularisasi, early stopping, dan data augmentasi digunakan untuk mengatasi overfitting, sedangkan meningkatkan kompleksitas model atau menggunakan fitur yang lebih informatif dapat membantu mengatasi underfitting.
Pemahaman terhadap istilah-istilah ini sangat penting dalam machine learning untuk mengevaluasi kinerja model dengan tepat, mengidentifikasi masalah yang mungkin terjadi, dan mengoptimalkan model untuk mendapatkan hasil yang lebih baik. Setiap istilah dan metrik memberikan informasi yang berbeda dan berguna dalam proses pengembangan dan penyempurnaan model machine learning.
Kami menerima jasa pembuatan program skripsi bagi teman teman yang memiliki judul Tugas Akhir bertema machine learning.
Portofolio
Berikut kami tampilkan beberapa portofolio yang pernah kami kerjakan. Lihat Selengkapnya


-untuk-Deteksi-Tumor-Otak.jpg)







-untuk-Prediksi-Pergerakan-Harga-Forex.jpg)











Oleh : Firda
Tanggal Publikasi :
Bebas DP bagi Skripsi dengan Judul dan Konsep yang Jelas
Sisa Kuota 2
Sisa Waktu : : : :































