Apa itu Text Mining
TweetDi era digital saat ini, data teks menjadi salah satu sumber informasi yang paling melimpah. Mulai dari email, dokumen, media sosial, hingga situs web, semuanya menghasilkan data teks yang terus bertambah setiap harinya. Namun, mengolah data teks dalam jumlah besar bukanlah tugas yang mudah bagi manusia. Di sinilah peran text mining dalam machine learning menjadi sangat penting.
Text mining adalah proses mengekstrak informasi dan wawasan berharga dari data teks yang tidak terstruktur. Dengan mengombinasikan teknik statistik, pembelajaran mesin (machine learning), dan pemrosesan bahasa alami (natural language processing), text mining memungkinkan kita untuk mengidentifikasi pola, tren, dan hubungan tersembunyi dalam data teks yang sulit untuk dianalisis secara manual.
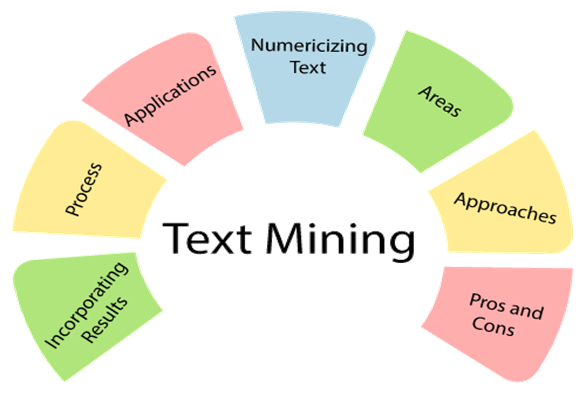
Tahapan Text Mining :
Tahapan Text Mining Proses text mining dalam machine learning dapat dibagi menjadi beberapa tahapan utama:
a. Pengumpulan Data Teks Tahap pertama dalam text mining adalah mengumpulkan data teks dari berbagai sumber seperti dokumen, email, media sosial, atau situs web. Data ini dapat berasal dari format yang berbeda-beda, seperti file teks biasa, PDF, HTML, atau bahkan data terstruktur seperti database.
b. Praproses Data Data teks mentah seringkali perlu diproses terlebih dahulu sebelum dapat dianalisis. Tahap ini melibatkan teknik seperti tokenisasi (memecah teks menjadi token seperti kata atau kalimat), penghapusan stopwords (kata-kata umum seperti "dan", "yang", atau "itu"), dan stemming (mengubah kata menjadi bentuk dasarnya).
c. Ekstraksi Fitur Setelah praproses, data teks diubah menjadi representasi numerik yang dapat dipahami oleh algoritma machine learning. Ini dapat dilakukan dengan menggunakan metode seperti bag-of-words, TF-IDF (Term Frequency-Inverse Document Frequency), atau Word Embeddings.
d. Pemodelan dan Pelatihan Pada tahap ini, algoritma machine learning dilatih menggunakan data teks yang telah diekstraksi fiturnya. Beberapa algoritma populer yang digunakan dalam text mining antara lain Naive Bayes, Support Vector Machines (SVM), Decision Trees, dan Deep Learning (jaringan saraf tiruan).
e. Evaluasi dan Implementasi Model yang telah dilatih kemudian dievaluasi kinerjanya menggunakan metrik seperti akurasi, presisi, recall, atau F1-score. Jika kinerjanya memenuhi syarat, model tersebut dapat diimplementasikan untuk tugas-tugas seperti klasifikasi teks, ekstraksi informasi, penggalian opini, atau analisis sentimen.
Aplikasi Text Mining
Aplikasi Text Mining dalam Machine Learning Text mining dalam machine learning memiliki banyak aplikasi praktis dalam berbagai bidang, antara lain:
a. Analisis Sentimen Analisis sentimen melibatkan proses mengidentifikasi opini, emosi, atau sentimen dalam data teks. Ini dapat digunakan untuk memahami persepsi pelanggan terhadap produk atau layanan, menganalisis respon terhadap kampanye pemasaran, atau memantau sentimen publik terhadap isu-isu tertentu.
b. Klasifikasi Dokumen Klasifikasi dokumen adalah proses mengkategorikan dokumen teks ke dalam kelas atau label tertentu. Contohnya adalah mengklasifikasikan email sebagai spam atau bukan spam, mengategorikan artikel berita berdasarkan topik, atau mengidentifikasi jenis dokumen hukum.
c. Ekstraksi Informasi Ekstraksi informasi melibatkan proses mengidentifikasi dan mengekstrak informasi spesifik dari data teks, seperti nama entitas, hubungan, atau fakta penting. Ini dapat digunakan dalam berbagai aplikasi seperti penggalian data biografis, ekstraksi informasi produk, atau ekstraksi informasi medis dari catatan klinis.
d. Penggalian Opini Penggalian opini adalah proses mengekstrak dan menganalisis opini atau pendapat dari data teks, seperti ulasan produk, komentar media sosial, atau survei pelanggan. Ini dapat memberikan wawasan yang berharga tentang persepsi dan preferensi konsumen.
e. Penemuan Pengetahuan Text mining juga dapat digunakan untuk menemukan pola, tren, atau hubungan tersembunyi dalam data teks yang dapat menyumbang pada penemuan pengetahuan baru. Contohnya adalah menganalisis tren penelitian dari publikasi ilmiah atau mengidentifikasi faktor risiko dari catatan medis pasien.
Tantangan dalam Text Mining
Tantangan dalam Text Mining Meskipun text mining dalam machine learning menawarkan banyak manfaat, ada beberapa tantangan yang perlu dihadapi:
a. Ambiguitas Bahasa Bahasa alami seringkali ambigu dan memiliki banyak makna tersirat. Ini dapat menyebabkan kesulitan dalam memahami konteks dan makna yang sebenarnya dalam data teks.
b. Keragaman Data Data teks dapat berasal dari berbagai sumber dengan format, gaya, dan variasi bahasa yang berbeda-beda. Ini menyulitkan dalam membangun model yang robust dan dapat beradaptasi dengan baik pada berbagai jenis data teks.
c. Skalabilitas Jumlah data teks yang terus bertambah secara eksponensial menuntut algoritma dan sistem yang dapat mengolah data dalam skala besar secara efisien.
d. Privasi dan Etika Banyak data teks yang mengandung informasi sensitif atau rahasia, sehingga aspek privasi dan etika harus dipertimbangkan dengan cermat dalam proses text mining.
Meskipun terdapat tantangan, kemajuan dalam bidang machine learning, pemrosesan bahasa alami, dan komputasi paralel terus mendorong perkembangan teknik text mining yang lebih canggih dan efektif. Dengan mengoptimalkan potensi text mining, kita dapat mengekstrak wawasan berharga dari data teks yang sebelumnya tersembunyi, sehingga membuka peluang baru dalam pengambilan keputusan berbasis data dan inovasi dalam berbagai sektor.
Bagi teman teman yang memiliki skripsi terkait Text mining, Kami dapat membantu agar bisa lulus tepat waktu, kami menerima jasa pembuatan aplikasi skripsi text mining untuk teknik informatika, sistem informasi dan ilmu komputer. dengan pengerjaan yang cepat dan biaya yang terjangkau bagi mahasiswa. tentu kami bisa menjadi solusi terbaik untuk
Portofolio
Berikut kami tampilkan beberapa portofolio yang pernah kami kerjakan. Lihat Selengkapnya


-untuk-Deteksi-Tumor-Otak.jpg)







-untuk-Prediksi-Pergerakan-Harga-Forex.jpg)











Oleh : Firda
Tanggal Publikasi :
Bebas DP bagi Skripsi dengan Judul dan Konsep yang Jelas
Sisa Kuota 2
Sisa Waktu : : : :































